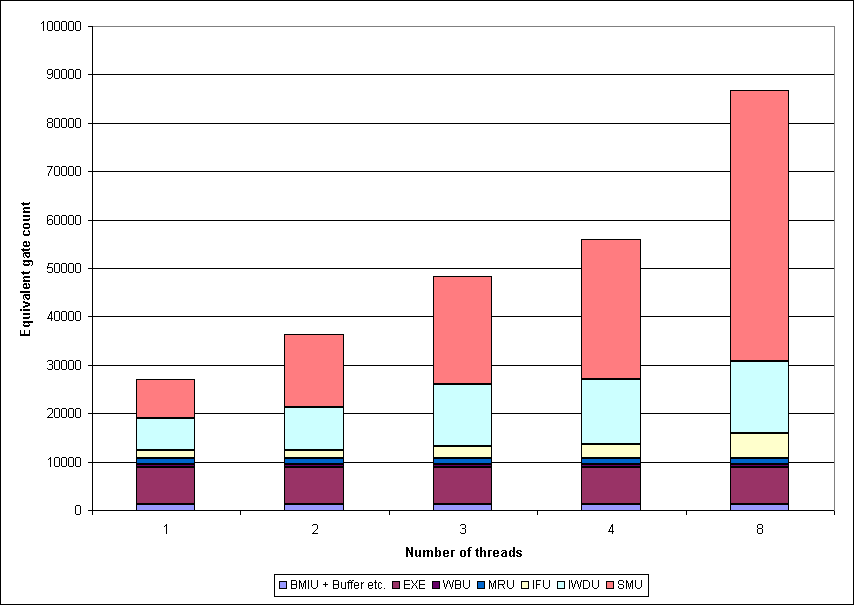
Abbildung 6.1: Anzahl Gatteräquivalente pro Block und Thread
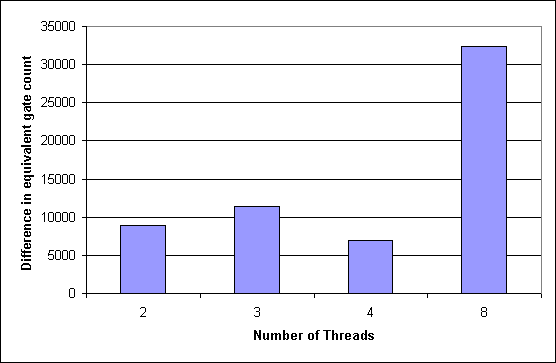
Abbildung 6.2: Differenzen in der Anzahl Gatteräquivalente pro Thread
Zusätzlich zum Zeitproblem tritt allerdings auch das Ressourcen-Problem im Testaufbau hervor: Die einfädige Pipeline mit den in Abschnitt 4.4.3 beschriebenen Befehlen ohne Multiplikation und Division vereinnahmt schon den gesamten FPGA. Sie entspricht damit einem Äquivalent von rund 27200 Gattern in 1296 CLB. Dies ist auch die maximale Anzahl konfigurierbarer Logikblöcke, die der Xilinx XC4036XL zur Verfügung stellen kann. Somit ist die Kapazität dieses Bausteins nahezu ausgeschöpft, auch wenn zu erwarten steht, daß durch einige dieser benutzten Blöcke noch weitere, sogenannte ,,unrelated logic`` beschrieben werden kann. Allerdings tritt dann die Frage nach der vollständigen Lösbarkeit des Verdrahtungsproblems verstärkt in den Vordergrund, die sich schon ab Auslastungen von weit unter 100% negativ bemerkbar machen kann.
Die konfigurierbaren Logikblöcke des feldprogrammierbaren Logikbausteins teilen sich auf die Funktionsblöcke des Prototypen auf (Tabelle 6.2). Alle Werte sind von Synthese zu Synthese kleinen Schwankungen unterworfen, und ein Logikblock kann durchaus mehrfach verwendet werden, solange sich die Funktionen nicht beeinträchtigen. Dies erklärt auch den Wert 0 bei der Anzahl konfigurierbarer Logikblöcke für die Microcode-ROM Unit:
|
In dieser Tabelle 6.2 sind zwei Zeilen für die Ausführungseinheit enthalten: EXE enthält den für den Prototypen geplanten und in Abschnitt 4.4.3 vorgestellten Mix aus Befehlen ohne Multiplikation und Division, aber mit den zusätzlichen Befehlen read_global0, read_global1, write_pc, write_optop, write_global0 und write_global1. EXEx enthält nun neben den in EXE implementierten Befehlen auch die Multiplikation.
Die aus den Differenzen der einzelnen Ergebnisse bestimmten Größen pro Thread lassen eine realistische Abschätzung für die benötigte Größe eines FPGA zu, auf dem die vollständige, vierfädige Pipeline implementiert werden kann:
Die einfädige Pipeline benötigt in der vorgestellten Version ohne Multiplikation und ohne Division 1296 CLB (rund 27200 Gatter). Dabei enthält die Stapelspeichereinheit 32 Speicherstellen à 32 Bit mit einem Schreibeingang und zwei Leseausgängen. Die Mikrocode-ROM-Einheit besteht aus den für den Prototypen vorgesehenen zwei Befehlen.
Eine sehr einfache und wenig optimierte Beschreibung der Mehrfädigkeit wurde für die Befehlsholestufe, die Puffereinheit mit Dekodierstufe und die Stapelspeichereinheit verwendet, um die Veränderungen im Ressourcenverbrauch abschätzen zu können. Danach ergeben sich die in Tabelle 6.3 enthaltenen durchschnittlichen Differenzwerte für diese drei Einheiten pro Kontrollfaden. Darin eingeschlossen sind auch die Kosten für die Verwaltung, also die zusätzlichen Kennungsbits.
|
Läßt man nun das Mapping auf den FPGA durchführen (wobei der Rechner feststellt, daß das Bauteil für diese Schaltung zu klein ist), so erhält man die in Tabelle 6.4 aufgeführten Zahlen für eine mehrfädige Pipelinestruktur. Entsprechend der Organisation der EXE wird auch hier wieder zwischen Pipeline ohne Multiplikation (Mapping) und mit Multiplikation (Mappingx) unterschieden. Im Vergleich zur einfädigen Pipeline ist nun der Ressourcenbedarf für die Synthese gestiegen: Sie benötigt ca. 150MB Arbeitsspeicher. Da sie nicht vollständig durchgeführt werden kann, existiert keine Laufzeitmessung.
|
Für einen achtfädigen Mikrocontroller wird aufgrund der errechneten Zahlen pro Kontrollfaden und Kennungsbit eine Prognose aufgestellt.
Die Ergebnisse sind in Abb. 6.1 für die Pipeline ohne Multiplikation graphisch dargestellt. Man erkennt, daß die Anzahl der Gatteräquivalente näherungsweise linear mit der Anzahl der Threads steigt, wobei ein zusätzlicher Offset für jedes hinzukommende Kennungsbit gerechnet werden muß. Dementsprechend ist die Differenz zur nächstkleineren Kontrollfadenzahl (Abb. 6.2) bei der Erhöhung von zwei auf drei Threads größer als bei der Erhöhung von drei auf vier (im ersten Fall muß ein zusätzliches Kennungsbit eingefügt werden, im zweiten Fall ist keine weitere Anpassung erforderlich). Der nächste größere Sprung käme also bei der Erweiterung auf fünf Threads, der folgende bei neun. Betrachtet man dies als Kriterium, so sollten für eine sinnvolle Ausnutzung der Ressourcen Zweierpotenzen als Anzahl der Kontrollfäden genutzt werden.
Um die einfädige Pipeline in der hier entworfenen Form in ein FPGA zu programmieren, reicht der XC4036XL gerade aus, wenn man die Multiplikation vernachlässigt (genauso wie die Division). Möchte man nun allerdings diesen Entwurf in eine vierfädige Pipeline umwandeln, so muß man auf einen XC4085XL ausweichen, der eine Schaltung mit rund 85000 Gatteräquivalenten aufnehmen kann. Die restlichen rund 20000 Gatteräquivalente werden aber sicherlich für den Prioritätenmanager und die Signaleinheit verbraucht werden.
Soll aus diesem Entwurf ein vollwertiger Mikrocontroller mit Analog/Digital-Wandler, RS232-, CAN-Bus- sowie anderen Schnittstellen hervorgehen, so muß für eine erste Implementierung auf einem programmierbaren Logikbaustein auch der Ressourcenbedarf dieser zusätzlichen Funktionseinheiten berücksichtigt werden.
Unter diesen Gesichtspunkten könnte man sich für einen Baustein
der Virtex-Familie von Xilinx entscheiden, der Platz für ungefähr
200000 Gatteräquivalente bietet (XCV200). Aufgrund der Eigenschaften
eines eingebetteten Systems wäre es zusätzlich sinnvoll, die
energiesparende Variante dieses Chips einzusetzen, den XCV200E. Da in der
Struktur des Komodo-Mikrocontrollers viele Speicherzellen auf dem FPGA
benötigt werden, bietet sich insbesondere eine Verwendung der ,,Extended
Memory``-Typen dieser Bausteinfamilie an (beispielsweise XCV405E). Diese
Betrachtungen werden allerdings nur aufgrund der vom Hersteller veröffentlichten
technischen Merkmale dieser FPGA durchgeführt [31];
eine genauere Kostenanalyse kann aus Zeitgründen nicht stattfinden.